Spark Operations-Transformations & Actions
- Murat Can ÇOBAN
- 25 Oca 2022
- 2 dakikada okunur
Güncelleme tarihi: 26 Oca 2022
Bu yazıda RDD ("Resilient Distributed Dataset) yani esnek dağıtık veri kümelerini inceliyor
olacağız. RDD üzerinde yapılan işlemleri örnekleriyle beraber sizlere anlatmaya çalışacağım. Transformation (Dönüşüm) ve Action (Eylem) olmak üzere iki konu altında inceleyeceğiz.
Öncelikle ihtiyacımız olan kütüphaneleri import ediyoruz. Daha sonrasında kendi bilgisayar donanımınıza göre bir SparkSession oluşturuyoruz.
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
spark = SparkSession.builder\
.master("local[2]")\
.appName("RDD-Olusturmak")\
.config("spark.executor.memory","4g")\
.config("spark.driver.memory","2g")\
.getOrCreate()
sc = spark.SparkContext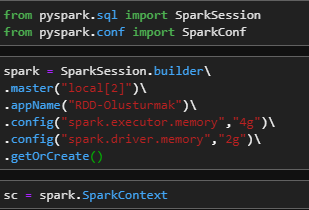
RDD OLUŞTURMAK
liste = [1,2,3,4,5,6,6,8,4,1]
liste_rdd = sc.parallelize(liste)
liste_rdd.take(10)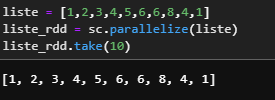
TRANSFORMATIONS (DÖNÜŞÜMLER)
Filter
Map
flatMap
Union
Intersection
Subtract
Distinct
Sample
Aşağıdaki gibi bir örnek RDD oluşturarak action fonksiyonlarımızı örnekler halinde inceleyelim.
liste = [1,2,3,4,5,6,6,8,4,1]
liste_rdd = sc.parallelize(liste)
liste_rdd.take(10)a) Filter
RDD içindeki değerleri verilen koşullara göre filtreleyerek yeni bir RDD oluşturur.
liste_rdd.filter(lambda x : x < 7).take(10)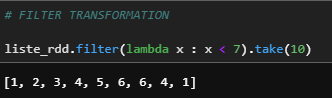
b) Map
RDD'nin her bir elemanına bir işlev uygulayarak yeni bir RDD döndürür.
liste_rdd.map(lambda x : x*x).take(10)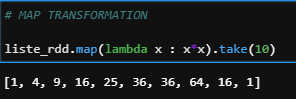
c) flatMap
RDD'nin her bir elemanının içindeki harflere bir işlev uygulayarak yeni bir RDD döndürür.
metin = ["emel eve gel","ali ata bak", "ahmet okula git"]
metin_Rdd = sc.parallelize(metin)
metin_Rdd.take(3)
metin_Rdd.flatMap(lambda x : x.split(" ")).take(3)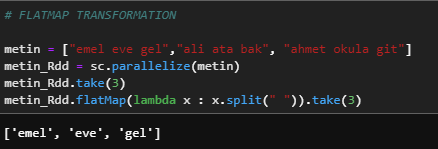
d) Union
İki veya daha fazla RDD arasında birleştirme işlemi uygular.
rdd2 = sc.parallelize([64,1,9,7,6,7,61,4])
rdd3 = sc.parallelize([658,4,3,1,1,2134])
rdd2.union(rdd3).take(50)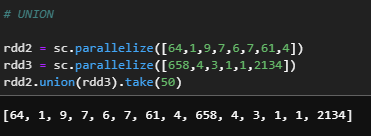
e) Intersection
İki RDD arasındaki ortak olan elemanları oluşturur.
rdd2.intersection(rdd3).take(54)
f) Subtract
İki RDD arasındaki farklı elemanları oluşturur.
rdd2.subtract(rdd3).take(10)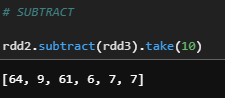
e) Distinct
Bir RDD'deki tekrarlanan elemanları eleyerek oluşturur.
liste_rdd.distinct().take(10)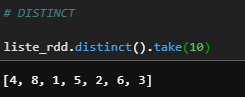
f) Sample
Verilen değerlere göre örnek bir RDD oluşturur..
liste_rdd.sample(True, 0.7, 31).take(10)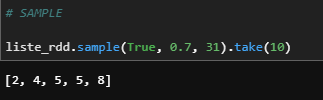
ACTIONS (EYLEMLER)
Take
Collect
Count
Top
Reduce
countByValue
takeOrdered
Aşağıdaki gibi bir örnek RDD oluşturarak action fonksiyonlarımızı örnekler halinde inceleyelim.
ornek = [1,2,3,4,5,6,6,8,4,1]
ornek_rdd = sc.parallelize(liste)
ornek_rdd.take(10)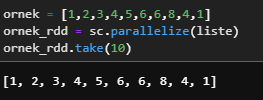
a) Take
N tane rastgele değeri döndürür.
ornek_rdd.take(7)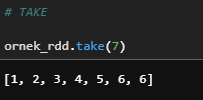
b) Collect
Tüm kayıtları bir satır listesi olarak döndürür.
ornek_rdd.collect()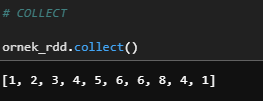
c) Count
Bir RDD'deki eleman sayısını getirir.
ornek_rdd.count()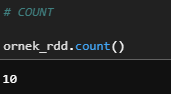
d) Top
En büyük n tane değeri getirir.
ornek_rdd.top(5)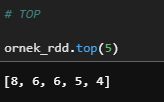
e) Reduce
RDD elemanları üzerinde işlemler yapar.
ornek_rdd.reduce(lambda x,y : x+y)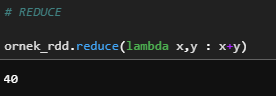
f) countByValue
Her bir elemanın kaç kere tekrarlandığını gösterir.
ornek_rdd.countByValue()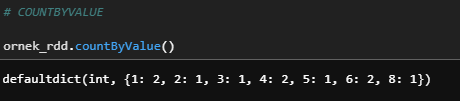
e) takeOrdered
RDD elemanlarını sıralayarak n tanesini getirir.
ornek_rdd.takeOrdered(7)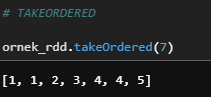
Bu yazımda Spark operasyonlarını transformation ve action olmak üzere örneklerle beraber anlatmaya çalıştım. Umarım faydalı olmuştur. Sorularınız için yorumlardan ulaşabilirsiniz.
Gelecek yazılarımızda görüşmek üzere, sağlıcakla kalın...
Comments